Intro Guides
This section consists of a series of introductory guides for researchers interested in learning how to implement the use of AI in their specific research domains.
Introduction to Agentic AI for Research
Read More
What is Agentic AI?
Agentic AI refers to artificial intelligence systems that act autonomously to accomplish complex, multi-step goals. Unlike generative models that create outputs in response to prompts, agentic systems can plan, decide, and coordinate multiple actions on our behalf. They break down high-level objectives into subtasks, select appropriate tools, and iteratively refine their outputs until the goal is achieved.
This evolution marks a shift from reactive AI toward systems that exhibit agency, adapting, persisting, and collaborating with minimal human supervision.
Why Agentic AI Matters for Research
Research increasingly involves tasks that are too complex to be automated with single-step models. Agentic AI introduces capabilities that make it relevant across domains:
- Scalability – handling literature reviews, data analysis, or simulation runs that would take humans weeks.
- Autonomy – coordinating entire workflows, from searching databases to generating reports.
- Adaptability – learning from context and feedback to refine results.
- Collaboration – orchestrating multiple specialized agents (planner, researcher, coder, analyst) to work together.
These features make agentic AI a general-purpose collaborator in fields as varied as law, healthcare, engineering, and the social sciences.
What Are Agentic AI Tasks?
| Task Type | What It Does | Research Examples |
|---|---|---|
| Research & information retrieval | Searches databases and compiles findings | Surveying recent literature on quantum computing; retrieving technical standards |
| Summarization & synthesis | Condenses and integrates multi-source information | Summarizing policy documents; creating executive research briefs |
| Reasoning & problem solving | Breaks down complex questions, simulates scenarios | Financial risk analysis; legal case mapping |
| Generative creation & editing | Drafts, edits, and refines multimodal outputs | Writing grant proposals; iteratively generating and debugging code |
| Data analysis & visualization | Cleans, models, and visualizes data | Processing environmental sensor data; building dashboards from survey results |
| Scheduling & planning | Coordinates calendars and workflows | Creating study timelines; orchestrating collaborative projects |
| Simulation & optimization | Explores outcomes, adjusts parameters, finds best solutions | Optimizing supply-chain logistics; testing alternative healthcare treatment plans |
By combining planning, reasoning, and tool use, agentic AI extends beyond content creation to full workflow management.
How Agentic AI Works (High-Level)
While architectures vary, most agentic systems share these components:
- Goal decomposition – A supervisor agent interprets a high-level goal and breaks it into subtasks.
- Specialized agents – Individual agents (researcher, planner, coder, tester, communicator) execute specific subtasks.
- Tool integration – Agents access external resources like databases, APIs, or file systems.
- Persistent memory – Systems track progress, preferences, and results across sessions.
- Feedback loops – Agents refine outputs via self-correction, cross-checking, or user input.
This modular design allows agentic systems to adapt and scale, adding or modifying agents without rebuilding the entire system.
Current Approaches and Design Patterns
Agentic AI employs several recurring patterns:
- Task decomposition and orchestration – Breaking goals into smaller tasks and assigning them to the right agents.
- Tool use and knowledge integration – Connecting with search engines, spreadsheets, or coding environments; retrieval-augmented generation grounds outputs in reliable sources.
- Persistent memory – Tracking states and results across sessions for continuity.
- Collaboration and self-validation – Agents cross-verify each other’s work to reduce errors.
- Reinforcement learning – Agents improve strategies through trial, error, and feedback.
Researchers are also exploring metrics to evaluate these systems, such as measuring how effectively agents coordinate and how efficiently they use tools.
Lower Barriers to Adoption: Agentic AI for All Researchers
Agentic AI is no longer confined to advanced labs. Adoption is accelerating thanks to:
- Open-source frameworks like LangChain and LlamaIndex for building agent workflows.
- Cloud platforms such as Amazon Bedrock offering memory, orchestration, and tool integration out-of-the-box.
- Prebuilt agents for coding, research, or data analysis that can be customized without deep ML expertise.
- No-code interfaces that let researchers prototype workflows visually.
These resources allow domain experts—whether scientists, lawyers, or educators—to design agentic workflows tailored to their research problems without needing to reinvent the underlying AI.
Ethics, Risks, and Responsible Use
Greater autonomy brings greater responsibility. Key challenges include:
- Trust and reliability – Ensuring outputs are consistent, auditable, and accurate in high-stakes contexts.
- Security – Protecting against prompt injection, impersonation, and other attacks in multi-agent systems.
- Bias and fairness – Preventing reinforcement of systemic biases in autonomous decision-making.
- Oversight – Keeping humans in the loop for validation, alignment, and accountability.
Governance frameworks are emerging to manage these issues, but transparency, safeguards, and ethical design remain essential.
Key Takeaways
- Agentic AI systems go beyond content generation; they plan, decide, and act autonomously.
- Their modular, multi-agent design makes them adaptable across disciplines.
- Common tasks include research, reasoning, data analysis, simulation, and workflow automation.
- Accessible frameworks and cloud platforms are lowering barriers to entry.
- Responsible adoption requires governance, safeguards, and continued human oversight.
Agentic AI represents a new era of autonomous intelligence, moving AI from reactive tools to proactive collaborators capable of tackling complex, cross-disciplinary challenges.
Introduction to Computer Vision (CV) for Research
Read More
What is Computer Vision?
Computer Vision (CV) is the field of artificial intelligence that enables computers to interpret and analyze visual information. Instead of working with structured data like tables or text, vision systems process raw pixels from images or video and turn them into meaningful data.
The goal is to transform visual input, whether from microscopes, drones, satellites, or everyday cameras, into structured information that can support analysis and decision-making. While most people encounter CV in daily life through smartphone face recognition or photo tagging, in research, it serves a far wider purpose: from detecting tumors in scans to mapping glaciers or digitizing cultural heritage.
Why CV Matters for Research
Visual data is now central to many areas of research, but its sheer scale makes it difficult to analyze manually. CV provides the ability to automate, scale, and accelerate visual analysis.
- Medicine – detecting tumors, fractures, or anomalies in medical scans.
- Environmental science – tracking deforestation, mapping coral reefs, or monitoring crop health from satellites.
- Astronomy – classifying galaxies and stars in telescope surveys.
- Archaeology – reconstructing 3D models of excavation sites from drone imagery.
- Engineering – inspecting infrastructure for cracks or defects.
- Digital humanities – transcribing and classifying handwriting from digitized manuscripts.
Across disciplines, CV enables researchers to extract knowledge from visual data that would otherwise require painstaking manual work.
What Are CV Methods?
| CV Method | What It Does | Research Examples |
|---|---|---|
| Image classification | Assigns labels to whole images | Diagnosing pneumonia from X-rays; classifying land cover in satellite imagery |
| Object detection | Finds and labels objects with bounding boxes | Counting wildlife in drone footage; detecting cracks in bridges |
| Image segmentation | Labels each pixel by class | Mapping tumor boundaries; separating land and water in satellite maps |
| Keypoint detection & pose estimation | Identifies landmarks or body joints | Tracking athlete motion; modeling artifact orientation in archaeology |
| Motion analysis & tracking | Follows objects across frames in video | Measuring glacier movement; studying crowd behavior |
| 3D reconstruction | Builds 3D models from 2D images | Digitizing heritage sites; creating city-scale urban maps |
| Image restoration & enhancement | Improves or recovers degraded images | Enhancing telescope images; super-resolving microscope photos |
These methods can be used alone or combined into powerful pipelines. For example, a marine biologist might use object detection to find fish, segmentation to map coral reefs, and motion tracking to monitor fish movement over time.
How CV Works (High-Level)
The technical details are complex, but the workflow can be understood in four main stages:
- Capture and preprocess – Images from cameras, satellites, or microscopes are collected and standardized (resized, denoised, normalized).
- Feature representation – Models convert pixels into abstract features such as edges, textures, or shapes. Modern deep networks learn these features automatically.
- Pattern recognition – Algorithms detect patterns, objects, or structures based on those features, whether that means identifying a tumor, finding a vehicle, or mapping vegetation.
- Output generation – The system produces usable results: a label, bounding box, segmentation map, motion track, or 3D model.
The Rise of Deep Learning and Vision Models
Early CV systems relied on hand-crafted features like edge detectors and texture filters. These methods were effective only for narrow tasks and often broke down in complex or noisy images.
Deep learning revolutionized CV. Convolutional Neural Networks (CNNs) made it possible to learn visual features directly from pixels, edges at low levels, shapes at mid-levels, and objects at higher levels. More recently, Vision Transformers (ViTs) have extended this by modeling long-range dependencies in images, improving accuracy in complex scenes.
Pretrained vision models trained on millions of images can now be fine-tuned for specific domains—such as pathology slides, archaeological photos, or satellite imagery, using relatively small datasets. This has drastically reduced the data and expertise needed to build effective CV systems.
Lower Barriers to Adoption: CV for All Researchers
Until recently, computer vision was accessible mainly to specialists with deep technical training. Today, it is far more approachable:
- Pretrained models are freely available in repositories like Hugging Face and TensorFlow Hub.
- Accessible libraries such as PyTorch, Keras, and OpenCV allow models to be run with minimal code.
- No-code platforms make it possible to upload images and train classifiers or detectors without programming.
- Cloud services (e.g., Google Vision AI, AWS Rekognition) provide ready-to-use tools for classification, detection, and OCR.
This democratization means that researchers across fields, from historians analyzing manuscripts to ecologists monitoring invasive species, can integrate CV into their workflows without becoming computer scientists.
Key Takeaways
- Computer Vision transforms raw pixels into structured, analyzable knowledge.
- It is used across disciplines, from medicine and astronomy to archaeology and environmental science.
- Deep learning models (CNNs, Vision Transformers) dominate, making CV systems more accurate and flexible.
- Lower barriers to entry mean researchers can now apply CV tools without needing advanced technical expertise.
As research becomes increasingly visual, CV provides the methods to see more, see faster, and uncover insights invisible to the naked eye.
Introduction to Generative AI for Research
Read More
What is Generative AI?
Generative AI is the branch of artificial intelligence that creates new content, text, images, music, video, code, or designs, based on patterns it learns from existing data. Unlike predictive or analytical models that classify or forecast, generative models produce plausible outputs that resemble the original data they were trained on.
The significance is that machines are no longer just tools for analyzing information; they can now act as creative collaborators. Researchers use generative AI to draft manuscripts, generate synthetic datasets, design molecules, simulate climate scenarios, or create visualizations, expanding the boundaries of how knowledge is produced and shared.
Why Generative AI Matters for Research
Generative AI has rapidly moved from experimental to mainstream. Surveys in 2024 showed adoption by a majority of organizations worldwide, with applications spreading across science, industry, and education. This momentum reflects not just hype but real integration into daily workflows.
For researchers, generative AI offers several advantages:
- Scalability – drafting or summarizing documents at scale.
- Creativity – producing new hypotheses, designs, or simulations.
- Efficiency – automating time-consuming tasks like figure generation, code writing, or data preparation.
- Accessibility – making tools like translation or summarization available without technical barriers.
At the same time, outcomes depend heavily on data quality. Projects succeed when models are trained or adapted on curated, domain-specific datasets, not just broad internet text. This makes careful data collection and stewardship a cornerstone of successful adoption.
What Are Generative AI Methods?
| Method | What It Does | Research Examples |
|---|---|---|
| Early probabilistic models | Used statistical patterns to generate sequences | N-gram models producing basic text or DNA fragments |
| Autoencoders & VAEs | Learn compressed data representations and sample new variants | Generating synthetic chemical structures; creating medical imaging variations |
| RNNs & LSTMs | Handle sequential data for longer outputs | Composing coherent music; generating full paragraphs of text |
| GANs | Pit a generator against a discriminator to produce realistic outputs | Creating high-quality synthetic microscopy images; producing realistic satellite imagery |
| Transformers | Use attention to model long-range dependencies, enabling large language models (LLMs) | Drafting scientific papers; writing software code |
| Diffusion models | Iteratively denoise random noise to create images or audio | Producing high-fidelity synthetic training data; generating cinematic video clips |
| Multimodal models | Combine text, image, audio, and video inputs and outputs | Interpreting scientific diagrams and related text; building interactive educational agents |
| Agentic AI | Plans and executes multi-step workflows autonomously | Automating supply-chain adjustments; resolving customer queries without human input |
How Generative AI Works (High-Level)
The mechanics vary by model, but the basic workflow is consistent:
- Training on data – Models ingest large datasets (text, images, or multimodal combinations) and learn statistical patterns.
- Learning representations – They build internal “maps” of language, visuals, or sounds, allowing them to capture meaning, style, and structure.
- Generating new outputs – When prompted, the model produces novel outputs consistent with what it has learned—such as drafting an abstract, generating a molecule, or simulating an environment.
- Refinement – Advanced techniques like reinforcement learning or adversarial feedback improve coherence, realism, and safety.
Current Models and Trends
- Large language models (LLMs) such as GPT, PaLM, LLaMA, and Claude generate text and code with high fluency.
- Diffusion models create strikingly realistic images and are being extended to video and audio.
- Multimodal AI (e.g., GPT-4o, Claude 3, Gemini) can combine reading, writing, seeing, and listening in a single system.
- Open-weight models (e.g., Meta’s Llama 3, Google’s Gemma) are closing the gap with commercial closed systems, enabling researchers to customize and run them locally.
This ecosystem gives researchers flexibility: use robust commercial APIs, or adapt open models to specialized domains.
Lower Barriers to Adoption: Generative AI for All Researchers
Generative AI once required massive compute and engineering expertise. Today, the barriers are much lower:
- Pretrained models are widely available, reducing the need for training from scratch.
- User-friendly platforms (Hugging Face, Replicate, OpenAI Studio) let researchers experiment quickly.
- No-code tools allow text or image generation through simple interfaces.
- Cloud services integrate generative capabilities directly into productivity platforms.
This democratization means researchers in any discipline, whether a historian generating synthetic archives, or a chemist exploring molecule variations, can access generative AI without deep technical knowledge.
Ethics, Regulation, and Responsible Use
With accessibility comes responsibility. Generative AI raises questions around:
- Bias and fairness – outputs may reflect skewed training data.
- Misinformation – generated text or images can be used to mislead.
- Intellectual property – training on copyrighted material raises legal and ethical debates.
- Transparency – researchers must validate, document, and audit outputs.
Governments and organizations are responding with evolving guidelines, emphasizing that human oversight remains essential. Responsible practices, such as careful dataset curation, output validation, and ethical review, ensure that generative AI serves research productively.
Key Takeaways
- Generative AI creates new content across text, images, video, code, and more.
- Its methods have evolved from simple statistical models to advanced deep learning systems like transformers and diffusion models.
- Applications span all research fields: drafting text, generating data, simulating environments, or automating workflows.
- Lower barriers mean researchers without technical expertise can now experiment with generative AI.
- Responsible adoption requires attention to ethics, bias, and data quality.
Generative AI is now a versatile, cross-disciplinary tool shaping the way researchers explore ideas, test hypotheses, and share discoveries.
Introduction to Natural Language Processing (NLP) for Research
Read More
What is NLP?
Natural Language Processing (NLP) is the branch of artificial intelligence that enables computers to understand, interpret, and generate human language. It draws on linguistics, computer science, and AI to transform unstructured text, such as research papers, field notes, or historical archives, into structured, analyzable information.
While most people encounter NLP in everyday tools like predictive text, voice assistants, or online translation, its applications in research are far broader. NLP can scan decades of publications, summarize thousands of documents, translate niche terminology, or uncover patterns in language that humans might never notice.
Why NLP Matters for Research
Text is one of the most abundant forms of data in research and often the most challenging to analyze at scale. Whether stored in physical archives or digital repositories, the volume is overwhelming. NLP changes that make large-scale analysis practical, fast, and replicable.
Examples across disciplines include:
- Public health – Mining millions of clinical trial reports for adverse drug reactions and mapping disease–symptom links.
- Environmental science – Extracting species and habitat data from biodiversity databases, field surveys, and citizen science submissions.
- Social science – Analyzing decades of newspaper articles or social media posts to detect shifts in public opinion and discourse.
- Legal research – Summarizing thousands of historical court decisions to reveal evolving legal precedents.
- Digital humanities – Classifying themes in literary works, correspondence, or political speeches to trace cultural and ideological shifts over centuries.
- Astrophysics – Extracting telescope observation parameters, experiment setups, and object descriptions from observatory logs.
- Archaeology – Translating excavation reports and extracting artifact details from multilingual archives.
- Education research – Analyzing student feedback at scale to identify common challenges and improve teaching methods.
These examples show why NLP is now seen as a general-purpose research tool, capable of adapting to any field where language is a source of knowledge.
Core NLP Methods and Research Uses
| NLP Method | What It Does | Research Examples |
|---|---|---|
| Text classification | Assigns categories to text | Classifying research papers by discipline; tagging field notes by habitat type |
| Named Entity Recognition (NER) | Identifies specific names or terms | Extracting chemical names from lab notebooks; identifying place names in historical maps |
| Sentiment & emotion analysis | Detects tone and emotion categories | Studying emotional framing in climate change debates; identifying affect in oral histories |
| Machine translation | Converts text between languages | Translating ethnographic interviews; processing multilingual government archives |
| Text summarization | Condenses text to key points | Creating short summaries of policy documents; condensing lengthy grant applications |
| Question answering & information retrieval | Finds relevant passages and returns answers | Querying global health reports for outbreak details; extracting figures from materials science datasets |
| Information extraction | Pulls structured data from unstructured text | Extracting experiment dates and outcomes from lab records; compiling event timelines from news archives |
| Relation extraction | Identifies relationships between entities | Mapping species–habitat associations; linking historical figures to events |
| Conversational agents | Interactive dialogue systems | Virtual research assistants for querying archaeological site data; lab assistants that help retrieve experimental protocols |
| Voice interfaces | Understands spoken input | Voice-controlled data entry during fieldwork; querying datasets hands-free in a lab |
These methods can be combined into powerful pipelines. For example, a climate change research assistant might classify documents by topic, extract named entities like “carbon dioxide levels,” detect relationships between those entities, and summarize findings in multiple languages for global collaborators.
How NLP Works
At its core, NLP involves three major stages:
- Understanding the input
The system starts by breaking text into smaller units: words, phrases, or subwords, then representing them as numbers that capture meaning (called embeddings). This is like mapping language into a mathematical space where similar concepts are close together. - Finding patterns and relationships
Machine learning models analyze these embeddings to detect patterns, identifying topics, recognizing entities, or connecting related concepts. Modern deep learning models, especially transformers, use self-attention to look at all words in context at once, understanding how they influence each other. - Producing useful output
Depending on the task, the model might produce a category label, extract specific terms, generate a summary, translate the text, or even carry on a conversation.
This high-level flow stays the same across disciplines; it’s the data and goals that change.
The Rise of Deep Learning and Language Models
Earlier NLP systems relied on:
- Rule-based approaches – Hand-crafted grammar rules, word lists, and patterns.
- Statistical models – Predictions based on word frequencies and probabilities.
These worked for narrow problems but broke down with nuanced or varied language.
Deep learning changed everything. Transformer-based models like BERT, GPT, and T5 can read entire passages at once, learn long-range relationships, and adapt quickly to new tasks. They’re pretrained on billions of words from books, articles, and websites to build a general understanding of language, then fine-tuned on smaller, domain-specific datasets for specialized research needs.
Language models, a subset of NLP models, are trained to predict the next word in a sequence. In doing so, they learn enough about language to summarize documents, answer questions, translate text, and even generate humanlike responses.
For researchers, this means:
- Faster model development with less data
- Better handling of domain-specific jargon
- Ability to integrate NLP tools into existing workflows without building systems from scratch
Lower Barriers to Adoption: NLP for All Researchers
Until recently, applying NLP in research often required:
- Large computing resources
- Extensive programming skills
- Months of custom model development
That’s no longer the case. Today, many ready-to-use tools and platforms allow researchers to apply NLP with minimal coding, or none at all. Examples include:
- Cloud-based NLP APIs (e.g., Google Cloud, AWS Comprehend, Azure Cognitive Services)
- Open-source libraries (e.g., spaCy, Hugging Face Transformers, NLTK) with pre-trained models
- No-code platforms that let you upload documents and run classification, extraction, or summarization
- Domain-specific toolkits for biomedical text, legal text, environmental science data, and more
In other words, you don’t have to be a machine learning expert to benefit from NLP. With accessible platforms, modest datasets, and clear research goals, you can begin exploring NLP’s capabilities in days, not months.
Key Takeaways
- NLP is a set of methods for extracting meaning from language and making text analysis scalable.
- It works across all research fields, from social science to astrophysics.
- Modern deep learning models have dramatically improved NLP’s flexibility and accuracy.
- Lower barriers mean researchers can now integrate NLP into projects without large budgets or technical teams.
By understanding what NLP can do and how it can be applied, you can unlock new insights from the vast amounts of text that shape your field.
Hands-On Guides
This section provides a list of tutorials and guides to help researchers implement the use of AI in their research and data analysis. Check back for more tutorials as this section continues to be updated.
- AI Sandbox Tutorial: Hugging Face Pipelines in Colab
- MIDAS Generative AI Guide: Your go-to resource for exploring the power of Generative AI and AI-assisted research.
AI Concepts and Terminology
AI tools are now part of everyday research and teaching. This section is a short, practical glossary to help you build shared vocabulary, understand what current systems can and cannot do, and make informed choices about when to use them. If you come across any terms in literature that you are unfamiliar with, this section is for you! You do not need a background in computer science to use this material. The goal is to give you enough clarity to ask good questions, evaluate claims, and discuss AI use with students and collaborators.
Terms you will see everywhere:
- Artificial Intelligence (AI) AI is the broad umbrella term for systems that perform tasks associated with human intelligence, such as recognizing patterns, making predictions, interpreting language, or supporting decisions.
- Machine Learning (ML) ML is a subset of AI. Instead of following hand-coded rules, ML systems learn patterns from data and use those patterns to make predictions or classifications.
- Deep Learning (DL) DL is a subset of ML that uses neural networks with many layers. Deep learning is widely used for images, speech, and language because it can learn complex patterns from large datasets.
- Generative AI (GenAI) Generative AI refers to models that can produce new content, such as text, images, code, audio, or video. These models generate outputs by learning statistical patterns from large datasets.Large Language Models (LLMs) LLMs are a class of generative deep learning models trained on large collections of text. They are designed to generate, summarize, translate, and reason over natural language by predicting likely sequences of words.
How do these terms relate?
You may see these terms used interchangeably, but they are not synonyms. While they are closely related, each refers to a distinct concept. The figure below shows how these terms relate to one another within a simple hierarchy.
- Artificial Intelligence is the broadest concept. It refers to any system designed to perform tasks that typically require human intelligence, such as recognizing patterns, making predictions, or interpreting language.
- Machine Learning sits within AI. Rather than relying on fixed rules, machine learning systems learn patterns from data and use those patterns to make predictions or classifications. Many modern AI systems rely on machine learning, but not all AI approaches do.
- Deep Learning is a subset of machine learning. It uses neural networks with many layers to learn complex representations from large amounts of data. Deep learning is especially effective for images, speech, and text, which is why it underpins most recent advances in AI.
- Generative AI is not a separate layer in the hierarchy. Instead, it describes what certain models can do. Generative models can produce new content, such as text, images, or code, based on patterns learned during training. Many generative systems are built using deep learning, but not all deep learning models are generative.
- Large Language Models are a specific subset of generative deep learning models. They focus on language tasks and are responsible for many of the text-based AI tools in use today. All LLMs are generative models built using deep learning, but not all generative models are language models.
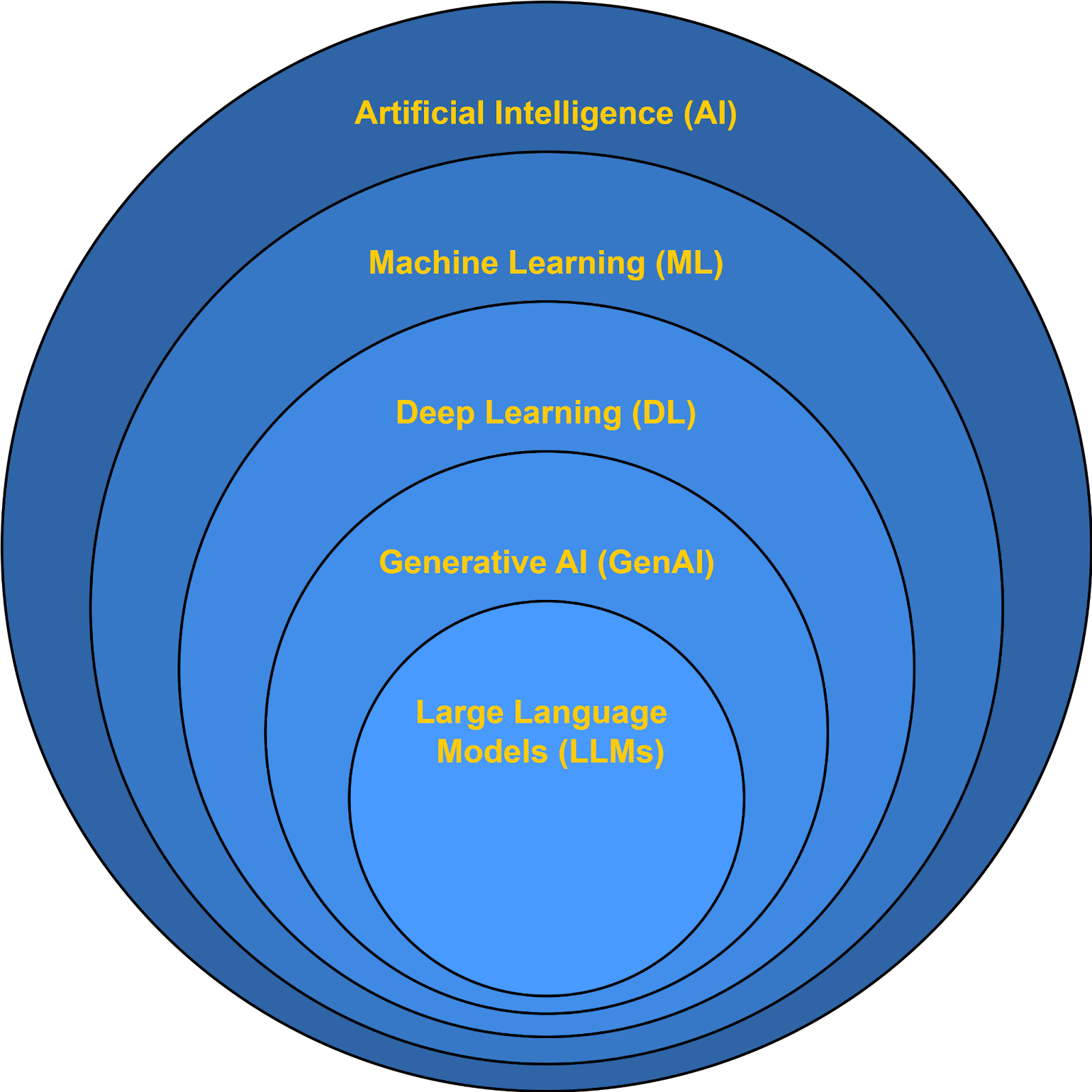
Image: Artificial Intelligence, Machine Learning, Deep Learning, Generative AI, and Large Language Models are nested and related concepts. For example, Large Language Models are a specific subset of Generative AI Models. They focus on language tasks and are responsible for many of the text-based AI tools in use today, like ChatGPT. All Large Language Models are Generative AI Models built using Deep Learning, but not all Generative AI Models are Large Language Models.
The Full Glossary
If you are new to the topic, start with the basic terms above, then move to the glossary. Looking for a term that’s not included? Please feel free to reach out to MIDAS so we can add it to our ever-growing list!
Additional Readings
Here you’ll find a series of academic papers, helpful resources, and additional materials to explore.
Academic Papers For Introduction to AI
This list of academic materials gives a look into how researchers are using AI in their research and education.
Research
- Towards Scientific Discovery with Generative AI: Progress, Opportunities, and Challenges
- Beyond the Hype: A Comprehensive Review of Current Trends in
- Generative AI Research, Teaching Practices, and Tools
- The Potential of Generative Artificial Intelligence Across Disciplines: Perspectives and Future Directions
- An Interdisciplinary Outlook on Large Language Models for Scientific Research
- The great AI witch hunt: Reviewers’ perception and (Mis)conception of generative AI in research writing
- Institutional Efforts to Help Academic Researchers Implement Generative AI in Research
Education
Beginner Resources to Learn AI Methods
Check out this collection of useful resources to help you learn AI methods.
General AI Introductions
- DeepLearning.AI – Basic of AI in Python course.
- Fast.ai NLP Course – Some coding experience, for people who want to learn how to apply deep learning.
- Nature Article – AI for research: A guide to choosing the right tool.
Natural Language Processing (NLP)
- Hugging Face NLP Course – Free interactive course introducing transformers and NLP tasks.
- spaCy Documentation & Tutorials – Great for applied NLP tasks like named entity recognition and text classification.
- Prompt engineering guide – Learn the capabilities and limitations of large language models.
Computer Vision (CV)
- OpenCV Tutorials – Classic computer vision methods, from image filtering to object detection.
- DeepLearning.AI: CV Specialization – Andrew Ng’s team, strong conceptual grounding.
Generative AI (GenAI)
- Hugging Face Diffusion Models Course – Friendly intro to image generation models.
- MIT Introduction to Generative AI – Foundation Models & Generative AI tutorial videos.
- Anthropic’s Prompt Library – Examples of prompts for GenAI across domains.
Agentic AI
- LangChain Documentation – Core framework for building AI agents.
- Microsoft Autogen Docs – Another open framework for multi-agent systems.
- Hugging Face Agents Overview – Simple intro to running models as “agents.”