Author: Josh Gardner, School of Information
For this project, MDST partnered with the City of Detroit’s Operations and Infrastructure Group. The Operations and Infrastructure Group manages the City of Detroit’s vehicle fleet, which includes vehicles of every type: police cars, ambulances, fire trucks, motorcycles, boats, semis … all of the unique vehicles that the City of Detroit uses to manage the many tasks that keep this city of over 700,000 people functioning.
 The Operations and Infrastructure Group was interested in exploring several aspects of its vehicle fleet, especially related to vehicle cost and reliability and their relationship to how their fleet of over 2,700 vehicles were maintained. This project kicked off at an especially unique time for the City of Detroit, as the city filed for bankruptcy in 2013, emerging in 2014 — cost-effectiveness with its vehicle fleet, one of the city’s most expensive and critical assets, was a key lever for operational effectiveness in the city.
The Operations and Infrastructure Group was interested in exploring several aspects of its vehicle fleet, especially related to vehicle cost and reliability and their relationship to how their fleet of over 2,700 vehicles were maintained. This project kicked off at an especially unique time for the City of Detroit, as the city filed for bankruptcy in 2013, emerging in 2014 — cost-effectiveness with its vehicle fleet, one of the city’s most expensive and critical assets, was a key lever for operational effectiveness in the city.
The city provided two data sources: a vehicles table, with one record for each vehicle purchased by the city — nearly 6700 vehicles, purchased as early as 1944 — and a maintenance table, with one record for each maintenance job performed on a vehicle owned by the city — over 200,000 records of jobs such as preventive maintenance, tire changes, body work, and windshield replacement.
Our team faced three common challenges in this project, which are common to many data science tasks. First, as a team of student data scientists who were not experts in city government, we needed to work with our partners to determine which questions our analysis should address. The possibilities for analysis were nearly endless — we needed to ensure that the ones we chose would assist the city in understanding and acting on their data. Second, this data was incomplete and potentially unreliable. This involved paper records being converted to digital records (like the vehicles from 1944), and data which reflected human coding decisions which may be inaccurate, arbitrary, or overlapping. Third, our team needed to recover complex structure from tabular data. Our data was in the format of two simple tables, but they contained complex patterns across time, vehicles, and locations. We needed techniques which could help us discover and explore these patterns. This is a common challenge with data science in the “real world”, where complex data is stored in tables.
Data Analysis and Modeling
Tensor Decomposition
Tensor decomposition describes techniques used to decompose tensors, or multidimensional data arrays. We applied the PARallel FACtors, or PARAFAC, decomposition. We refer readers to our paper or to (Kolda and Bader 2009) for details on this technique. Also check out (Bader et al. 2008) for an interesting application of this technique to tracing patterns in the Enron email dataset that we enjoyed reading.
Applying the PARAFAC allowed us to automatically extract and visualize multidimensional patterns in the vehicle maintenance data. First, we created data tensors as shown below. Second, we applied the PARAFAC decomposition to these tensors, which produced a series of factor matrices which best reconstructed the original data tensor.
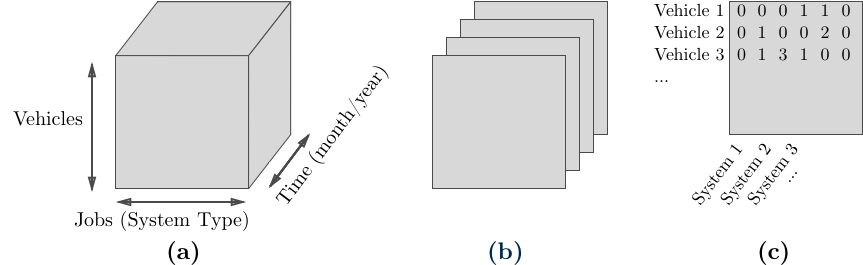

Left: Depiction of (a) 3-mode data tensor; (b) the same tensor as a stacked series of frontal slices, or arrays; (c) an example single frontal slice of a vehicle data tensor used in this analysis (each entry corresponds to the count of a specific job type for a vehicle at a fixed time). Right: Visual depiction of the PARAFAC decomposition.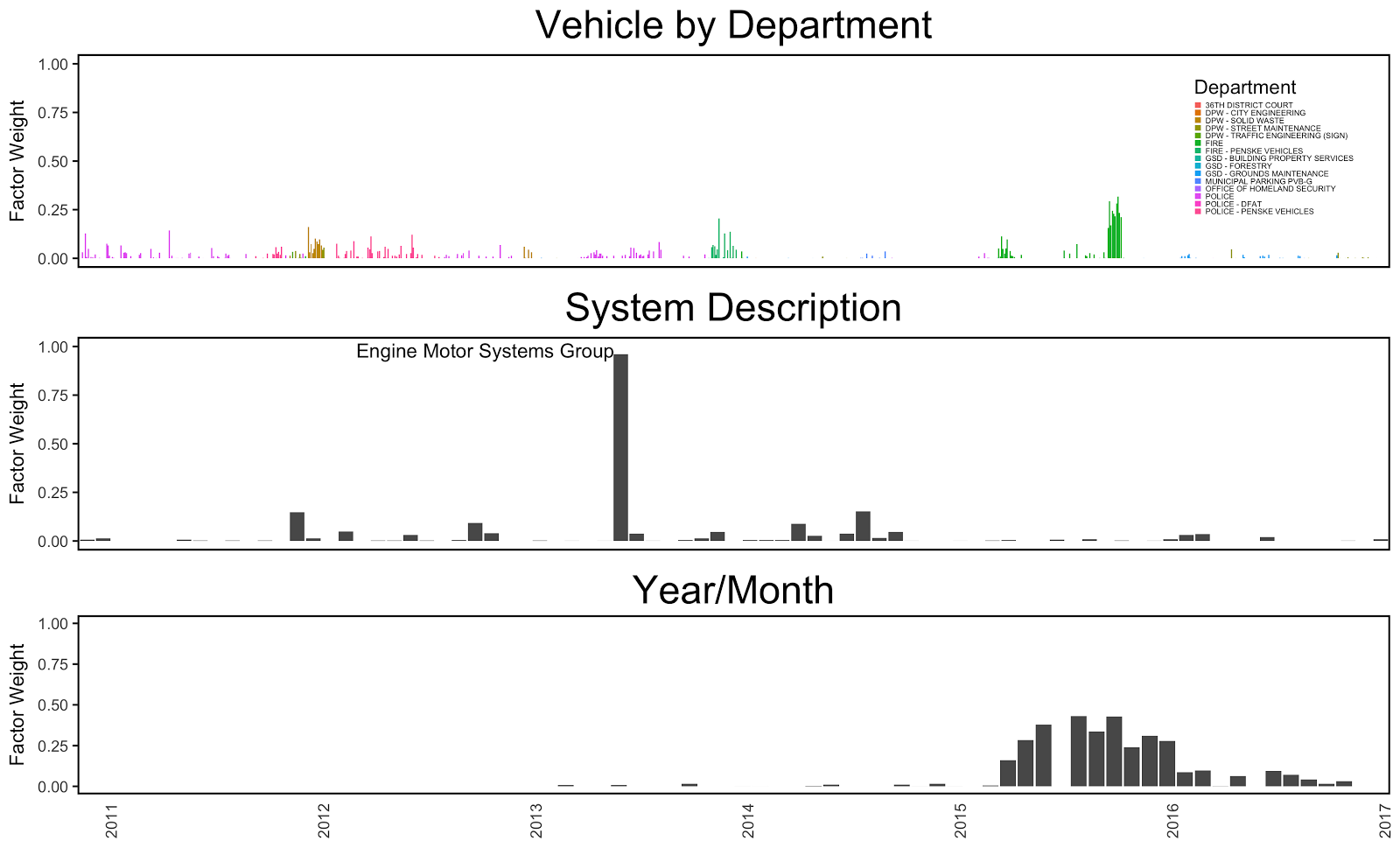
We generated and explored “three-way plots” of these factors using two different types of time axis: absolute time, which allowed us to model things like seasonality over time; and vehicle lifetime, which allowed us to model patterns in how maintenance occurred over a vehicle’s lifetime (relative to when it was purchased). We show one such plot below, which demonstrates unique maintenance patterns for the 2015 Smeal SST Pumper fire truck (shown in the photo in the introduction above); for a detailed analysis of this and other three-way plots from the Detroit vehicles data, check out the paper. Here, we will mention that PARAFAC helped us discover unique patterns in maintenance, including a set of vehicles which were maintained at different specialty technical centers by Detroit, without us specifically looking for them or even knowing these patterns existed.
Differential Sequence Mining
Our tensor decomposition analysis demonstrated several interesting patterns, both in absolute time and in vehicle lifetime. As a second step of data exploration, we decided to investigate whether there were statistically unique sequences of vehicle maintenance. To do this, we employed a differential sequence mining algorithm to compare common sequences between different groups, and identify whether the differences in their prevalence between groups is statistically significant. We compared each vehicle make/model to the rest of the fleet for this analysis.
For nearly every vehicle, we found that the most common sequences were significantly different from the rest of the fleet. This indicated that there were strong, unique patterns in the sequences of these make/models relative to the rest of the fleet. This insight confirmed our finding from the tensor decomposition, demonstrating that there were useful patterns in maintenance by make/model that a sequence-based predictive modeling approach could utilize.
Predictive LSTM Model
Having demonstrated strong patterns in the way different vehicle make/models were maintained over time, we then explored predictive modeling techniques which could capture these patterns in a vehicles’ maintenance history, and use them to predict its next maintenance job.
We used a common sequential modeling algorithm, the Long Short-Term Memory network. This is a more sophisticated version of a normal neural network which, instead of evaluating just a single observation (i.e., a single job or vehicle), captures information about the observations it has seen before (i.e., the vehicles’ entire previous history). This allows the model to “remember” vehicles’ past repairs, and use all of the available historical information to predict the next job.
The specific model we used was a simple neural network from a prior work on predicting words in sentences because of its ability to model complex sequences while avoiding over-fitting (Zaremba et al. 2014). In our paper, we demonstrate that this model is able to predict sequences effectively, even with a very small training set of only 164 vehicles and predicting on unseen test data of the same make/model (we used Dodge Chargers for this prediction because these were the largest set of available data, as the most common vehicle in the data set we evaluated). While we don’t have any direct comparison for the model performance, we demonstrated that it achieves a perplexity score of 15.4, far outperforming a random baseline using the same distribution as the training sequences (perplexity of 260), and below state-of-the-art language models on the Penn Treebank (23.7 for the original model ours is based on) or the Google Billion Words Corpus (around 25) (Kuchaiev and Ginsburg 2017).
Conclusion
Working with real-world data that contains complex, multidimensional patterns can be challenging. In this post, we demonstrated our approach to analyzing the Detroit vehicles dataset, applying tensor decomposition and differential sequence mining techniques to discover time- and vehicle-dependent patterns in the data, and then building an LSTM predictive model on this sequence data to demonstrate the ability to accurately predict a vehicle’s next job, given its past maintenance history.
We’re looking forward to continuing to explore the Detroit vehicles data, and have future projects in the works. We’d like to thank the General Services Department and the Operations and Infrastructure Group of the City of Detroit for bringing this project to our attention and making the data available for use.
For more information on the project, check out the full paper here.