Danai Koutra
Assistant Professor
Computer Science and Engineering, College of Engineering
Associate Professor of Electrical Engineering and Computer Science, College of Engineering
The GEMS (Graph Exploration and Mining at Scale) Lab develops new, fast and principled methods for mining and making sense of large-scale data. Within data mining, we focus particularly on interconnected or graph data, which are ubiquitous. Some examples include social networks, brain graphs or connectomes, traffic networks, computer networks, phonecall and email communication networks, and more. We leverage ideas from a diverse set of fields, including matrix algebra, graph theory, information theory, machine learning, optimization, statistics, databases, and social science.
At a high level, we enable single-source and multi-source data analysis by providing scalable methods for fusing data sources, relating and comparing them, and summarizing patterns in them. Our work has applications to exploration of scientific data (e.g., connectomics or brain graph analysis), anomaly detection, re-identification, and more. Some of our current research directions include:
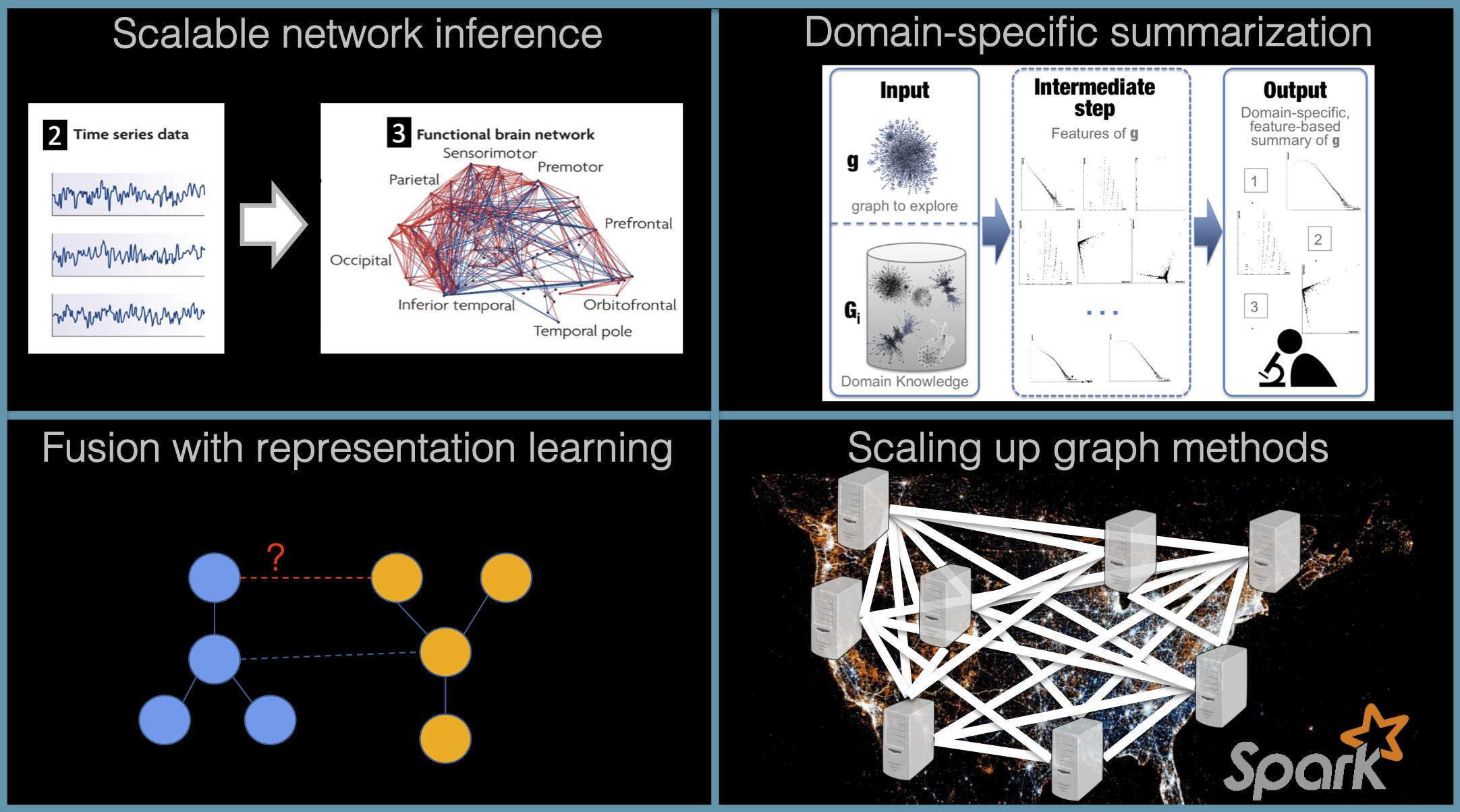
*Scalable Network Discovery from non-Network Data*: Although graphs are ubiquitous, they are not always directly observed. Discovering and analyzing networks from non-network data is a task with applications in fields as diverse as neuroscience, genomics, energy, economics, and more. However, traditional network discovery approaches are computationally expensive. We are currently investigating network discovery methods (especially from time series) that are both fast and accurate.
*Graph similarity and Alignment with Representation Learning*: Graph similarity and alignment (or fusion) are core tasks for various data mining tasks, such as anomaly detection, classification, clustering, transfer learning, sense-making, de-identification, and more. We are exploring representation learning methods that can generalize across networks and can be used in such multi-source network settings.
*Scalable Graph Summarization and Interactive Analytics*: Recent advances in computing resources have made processing enormous amounts of data possible, but the human ability to quickly identify patterns in such data has not scaled accordingly. Thus, computational methods for condensing and simplifying data are becoming an important part of the data-driven decision making process. We are investigating ways of summarizing data in a domain-specific way, as well as leveraging such methods to support interactive visual analytics.
*Distributed Graph Methods*: Many mining tasks for large-scale graphs involve solving iterative equations efficiently. For example, classifying entities in a network setting with limited supervision, finding similar nodes, and evaluating the importance of a node in a graph, can all be expressed as linear systems that are solved iteratively. The need for faster methods due to the increase in the data that is generated has permeated all these applications, and many more. Our focus is on speeding up such methods for large-scale graphs both in sequential and distributed environments.
*User Modeling*: The large amounts of online user information (e.g., in social networks, online market places, streaming music and video services) have made possible the analysis of user behavior over time at a very large scale. Analyzing the user behavior can lead to better understanding of the user needs, better recommendations by service providers that lead to customer retention and user satisfaction, as well as detection of outlying behaviors and events (e.g., malicious actions or significant life events). Our current focus is on understanding career changes and predicting job transitions.