
More than 50 students took part in the Student Poster Competition during the 3rd Annual MIDAS Symposium.
The winning entries can be viewed at http://midas.umich.edu/2017-symposium/winning-posters/
More than 50 students took part in the Student Poster Competition during the 3rd Annual MIDAS Symposium.
The winning entries can be viewed at http://midas.umich.edu/2017-symposium/winning-posters/
The University of Michigan Library system and the Data Acquisition for Data Sciences program (DADS) of the U-M Data Science Initiative (DSI) have recently joined forces to license a major data resource capturing parcel-level information about the property market in the United States.
The data were licensed from the Corelogic corporation, who have assimilated deed, tax and foreclosure information on nearly all properties in the entire US. Coverage dates vary by county, some county records go back fifty years. Coverage is more comprehensive from the 1990s to the present.
These data will support a variety of research efforts into regional economies, economic disparities, trends in land-use, housing market dynamics, and urban ecology, among many other areas.
The data are available on the Turbo Research Storage system for users of the U-M High Performance Computing infrastructure, and via the University of Michigan Library.
To access the data, researchers must first sign a MOU; contact Senior Associate Librarian Catherine Morse cmorse@umich.edu for more information, or visit https://www.lib.umich.edu/database/corelogic-parcel-level-real-estate-data.
Asst. Prof. Emanuel Gull, Physics, is offering a mini-course introducing the Python programming language in a four-lecture series. Beginners without any programming experience as well as programmers who usually use other languages (C, C++, Fortran, Java, …) are encouraged to come; no prior knowledge of programming languages is required!
For the first two lectures we will mostly follow the book Learning Python. This book is available at our library. An earlier edition (with small differences, equivalent for all practical purposes) is available as an e-book. The second week will introduce some useful python libraries: numpy, scipy, matplotlib.
At the end of the first two weeks you will know enough about Python to use it for your grad class homework and your research.
Special meeting place: we will meet in 340 West Hall on Monday September 11 at 5 PM.
Please bring a laptop computer along to follow the exercises!
For more information: https://sites.lsa.umich.edu/gull-lab/teaching/physics-514-fall-2017/introduction-to-python/
Learn about graduate programs that will prepare you for success in computationally intensive fields — pizza and pop provided
Times / Locations:
Want to effectively use untapped data that is all around us—from traffic streaming data to social media data—to discover a desired solution? A new University of Michigan-Dearborn graduate program is going to teach students to do just that.
The Amazon Research Awards (ARA) program offers awards of up to $80,000 in cash and $20,000 in AWS promotional credits to faculty members at academic institutions in North America and Europe for research in these areas:
The ARA program funds projects conducted primarily by PhD students or post docs, under the supervision of the faculty member awarded the funds. To encourage collaboration and the sharing of insights, each funded proposal team is assigned an appropriate Amazon research contact. Amazon invites ARA recipients to speak at Amazon offices worldwide about their work, meet with Amazon research groups face-to-face, and encourages ARA recipients to publish their research outcome and commit related code to open-source code repositories.
Submissions are to be made online and details including rules and who may apply are located here.
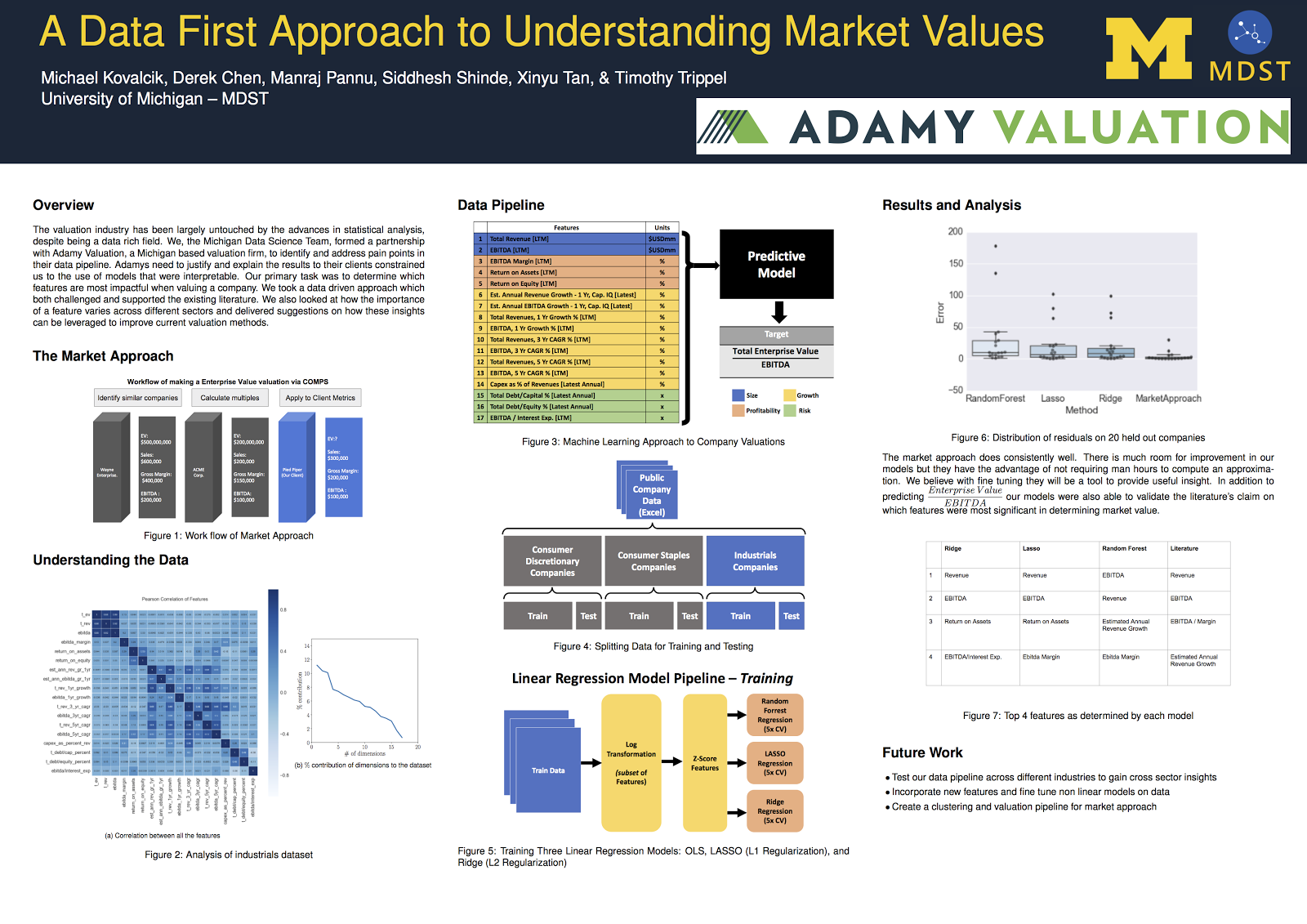
Authors: Michael Kovalcik, College of Engineering; Xinyu Tan, College of Engineering; Derek Chen, Ross School of Business.
![]() The Michigan Data Science Team partnered with Adamy Valuation, a Grand Rapids-based valuation firm, to bring data-driven insights to business equity valuation. Business valuation firms determine the market value of business interests in support of a variety of different types of transactions typically involving ownership interests in private businesses. Valuation firms, such as Adamy Valuation, deliver this assessment, which includes a detailed report explaining the reasons why they believe it to be fair.
The Michigan Data Science Team partnered with Adamy Valuation, a Grand Rapids-based valuation firm, to bring data-driven insights to business equity valuation. Business valuation firms determine the market value of business interests in support of a variety of different types of transactions typically involving ownership interests in private businesses. Valuation firms, such as Adamy Valuation, deliver this assessment, which includes a detailed report explaining the reasons why they believe it to be fair.
Valuations are performed by expert financial analysts, who use their knowledge about the factors that influence value to manually assess the value of the equity. Shannon Pratt’s Valuing a Business suggests that there are two key factors in particular that influence value: risk and size. Risk is a measure of uncertainty relating to the company’s future and can be assessed by looking at total debt and cash flows. Size refers to a company’s economic power. Larger companies will spend and make more than smaller ones. While these factors are quite informative, the degree to which they influence value varies a lot from industry to industry and even from company to company. Therefore, a valuation firm will often adjust their models manually to account for additional features, using knowledge gained from years of experience and industry expertise.
Our goals were to conduct a data-driven analysis of the valuation process and to build a predictive model that could learn to make value adjustments from historical data. A critical requirement of our approach was that the resulting model must be interpretable. An algorithm that is extremely accurate but offers no insight into how the prediction was made or what features it was based off of is of no use to Adamy Valuation because, at the end of the day, they must be able to validate the reasoning behind their assessment.
 The Data Pipeline
The Data PipelineWhile our goal is to value private companies, data related to these companies is difficult to come by. Business valuation analysts address this issue by using market data from public companies as guideline data points to inform the valuation of a private subject company. To this end, we acquired a dataset of 400 publicly-traded companies along with 20 financial metrics that are commonly used during valuation. We cleaned this dataset to only contain features that are relevant to private companies so that the model learned on public companies could later be applied to value private companies.
We separate financial metrics into four categories: Size, Profitability, Growth, and Risk, as indicated by the colors in Fig. 1. Our goal was to determine which of the four categories, or more specifically, which features in these categories, contribute the most to:
 where TEV represents the Total Enterprise Value a measure of a company’s market value, adjusting for things like debt and cash on hand, and EBITDA stands for earnings before interest, tax, depreciation, and amortization. EBITDA allows analysts to focus on operating performance by minimizing the impact of non-operating decisions such as which tax rates they must pay and the degree to which their goods depreciate. In other words EBITDA gives a clearer value for head to head comparisons of company performance. Valuation firms typically examine the ratio of TEV and EBITDA instead of examining TEV or EBITDA directly, because the ratio standardizes for the size of the company, making it easier to make apples to apples comparisons with companies that may be much larger or smaller, but are otherwise similar.
where TEV represents the Total Enterprise Value a measure of a company’s market value, adjusting for things like debt and cash on hand, and EBITDA stands for earnings before interest, tax, depreciation, and amortization. EBITDA allows analysts to focus on operating performance by minimizing the impact of non-operating decisions such as which tax rates they must pay and the degree to which their goods depreciate. In other words EBITDA gives a clearer value for head to head comparisons of company performance. Valuation firms typically examine the ratio of TEV and EBITDA instead of examining TEV or EBITDA directly, because the ratio standardizes for the size of the company, making it easier to make apples to apples comparisons with companies that may be much larger or smaller, but are otherwise similar.
To study how feature importance varied across industries, we categorized each public company into one of three separate sectors:
Our goal is not just to accurately estimate value, but also to identify key relationships between a company’s observable metrics and its ratio of TEV to EBITDA.We study 17 financial metrics, many of which have complex relationships with the ratio of TEV and EBITDA. To identify these relationships, we model the problem as a regression task. We use two simple but widely-used frameworks: linear models and tree-based models because both methods offer insight into how the predictions are actually made.
After fitting our models to the data, we identified the most predictive features of company value across industries, and compared this to profit margin and size, the metrics most commonly used in Valuing a Business. For our linear models we used the coefficients in our regression equation to determine which features were most important. For our random forest model we used the feature importance metric which ranks features according to the information gained during the fitting process.
 Results
ResultsThe figure to the right depicts the accuracy our models versus the market approach (also known as comparable approach), the method used by valuation firms. With the size of the dataset and the specificity of the market approach we are not surprised that it outperforms our models. Rather we are showing here that our models have a reasonable enough degree of accuracy to trust the interpretation of the features.
 Also on the right we show the top 3 features, according to information gain, per industry as learned by our random forest model. The larger the bar the more insightful that variable was for predictions.The features we see turning up in our model are indicators of profitability and size which agree with the existing knowledge in the literature. It is interesting to note that return on assets shows up in each sector which intuitively means the market values those companies that get high returns regardless of the sector.
Also on the right we show the top 3 features, according to information gain, per industry as learned by our random forest model. The larger the bar the more insightful that variable was for predictions.The features we see turning up in our model are indicators of profitability and size which agree with the existing knowledge in the literature. It is interesting to note that return on assets shows up in each sector which intuitively means the market values those companies that get high returns regardless of the sector.
Remember our goal was to predict TEV/EBITDA, which is a measure of company’s total value after standardizing for things such as size, tax structure, and number of other factors. There were 5 distinct predictors that really stood out in our analysis.
Return on Assets is a measure of a company’s efficiency in generating profit.
Total Revenue is also known as total sales and is a measurement of how much a company receives from the sale of goods and services.
EBITDA 1 year growth: EBITDA is a measure of profitability and growing EBITDA means growing profit and increasing value of a company.
A Capital Expenditure(Capex) is the amount of money that a company invested in property and equipment. Capex is often linked to the expansion or contraction of a business and is therefore a measure of growth. Looking at Capex as percentage of revenue provides a normalized measurement for comparison.
EBITDA Margin serves as an indicator of a company’s operating profitability. Higher EBITDA margin means the company is getting more EBITDA for every dollar of revenue.
MSSISS or the Michigan Student Symposium for Interdisciplinary Statistical Sciences is an annual conference hosted by the University of Michigan. MSSISS brings together statistics works from a number of different fields including computer science, electrical engineering, statistics, biostatistics, and industrial operations. Our poster was particularly interesting as it was the only one with a financial application. The novelty of our project drew in a number of viewers and impressed the judges. A major component of our poster score was determined by our ability to communicate our results to people outside the field. We received a certificate of merit for our work and ability to communicate it to the other attendees at the conference.
The Michigan Institute for Data Science (MIDAS) is convening a research working group on mobile sensor analytics. Mobile sensors are taking on an increasing presence in our lives. Wearable devices allow for physiological and cognitive monitoring, and behavior modeling for health maintenance, exercise, sports, and entertainment. Sensors in vehicles measure vehicle kinematics, record driver behavior, and increase perimeter awareness. Mobile sensors are becoming essential in areas such as environmental monitoring and epidemiological tracking.
There are significant data science opportunities for theory and application in mobile sensor analytics, including real-time data collection, streaming data analysis, active on-line learning, mobile sensor networks, and energy efficient mobile computing.
Our working group welcomes researchers with interest in mobile sensor analytics in any scientific domain, including but not limited to health, transportation, smart cities, ecology and the environment.
Where and When:
Noon to 2 pm, April 13, 2017
School of Public Health I, Room 7625
Lunch provided
Agenda:
Brief presentations about challenges and opportunities in mobile sensor analytics (theory and application);
A brief presentation of a list of funding opportunities;
Discussion of research ideas and collaboration in the context of grant application and industry partnership.
Future Plans: Based on the interest of participants, MIDAS will alert researchers to relevant funding opportunities, hold follow-up meetings for continued discussion and team formation as ideas crystalize for grant applications, and work with the UM Business Engagement Center to bring in industry partnership.
Please RSVP. For questions, please contact Jing Liu, Ph.D, MIDAS research specialist (ljing@umich.edu; 734-764-2750).
The National Academies Committee on Applied and Theoretical Statistics has released proceedings from its June 2016 workshop titled “Refining the Concept of Scientific Inference When Working with Big Data,” co-chaired by Alfred Hero, MIDAS co-director and the John H Holland Distinguished University Professor of Electrical Engineering and Computer Science.
The report can be downloaded from the National Academies website.
The workshop explored four key issues in scientific inference:
The workshop brought together statisticians, data scientists and domain researchers from different biomedical disciplines in order to identify new methodological developments that hold significant promise, and to highlight potential research areas for the future. It was partially funded by the National Institutes of Health Big Data to Knowledge Program, and the National Science Foundation Division of Mathematical Sciences.
The Michigan Data Science Team and the Michigan Student Symposium for Interdisciplinary Statistical Sciences (MSSISS) have partnered with the City of Detroit on a data challenge that seeks to answer the question: How can blight ticket compliance be increased?
An organizational meeting is scheduled for Thursday, Feb. 16 at 5:30 p.m. in EECS 1200.
The city is making datasets available containing building permits, trades permits, citizens complaints, and more.
The competition runs through March 15. For more information, see the competition website.
MIDAS is a unit of the Office of the Vice President for Research
![]()
Copyright © 2020 The Regents of the University of Michigan